
R provee un entorno de software libre para trabajar con estadísticas y gráficos.
Esta guía describe cómo:
- usar R para aritmética simple
- cargar datos desde un archivo shape y mapearlo
- hacer transformación de coordenadas
- dibujar puntos en un mapa
Puedes:
- Elegir R Statistics en la sección de Spatial Tools del menú y aparecerá una ventana de terminal corriendo R.
- En la línea de commandos ejectuar R y se iniciará en esa terminal.
No le tengas miedo a la línea de comandos porque es una grandiosa fuente de poder. Puedes usar las flechas hacia arriba y hacia abajo para llamar nuevamente a comandos que ya hayas ejecutado y editar los errores que puedas haber cometido. Si te atascas, aprieta CTRL-C y podrás ejectuar un nuevo comando.
Casi todo en R es una función, incluída la función de salir. Escribe q() y aprieta enter. Si sólo escribes q, verás el código fuente de la función q.
R te preguntará si quieres guardar tu espacio de trabajo como un archivo de imagen de datos R. Cuando arranques nuevamente R desde un directorio con .RData, los datos serán recuperados desde ahí.
R es escencialmente un programa de línea de comandos aunque también están disponibles algunas interfaces gráficas. Escribes una línea de código, aprietas enter, y el intérprete de R evalúa el código e imprime los resultados.
Puedes empezar con artimética simple:
> 3*2
[1] 6
> 1 + 2 * 3 / 4
[1] 2.5
> sqrt(2)
[1] 1.414214
> pi * exp(-1)
[1] 1.155727
Hay un completo rango de funciones aritméticas, trigonométricas y estadísticas, y hay miles más disponibles como paquetes en el archivo CRAN.
El prompt principal de R es >, pero también hay un prompt de continuación, +, que aparece si R espera más datos de entrada para que una expresión sea válida. Lo verás si te olvidas de cerrar un corchete o un paréntesis.
> sqrt(
+ 2
+ )
[1] 1.414214
Debes estar preguntándote qué significa ese ‘uno’ entre corchetes en la salida. Eso te está diciendo que el resultado es un número. R puede almacenar cosas en vectores de una dimensión, matrices de dos dimensiones y matrices multidimensionales. Hay muchas funciones que pueden generar estas cosas. Por ejemplo, esta secuencia simple:
> seq(1,5,len=10)
[1] 1.000000 1.444444 1.888889 2.333333 2.777778 3.222222 3.666667 4.111111
[9] 4.555556 5.000000
Ahora puedes ver que el [9] nos está diciendo que 4.555 es el noveno valor en el vector.
Si construyes una matriz obtienes valores en filas y columnas:
> m=matrix(1:12,3,4)
> m
[,1] [,2] [,3] [,4]
[1,] 1 4 7 10
[2,] 2 5 8 11
[3,] 3 6 9 12
Los elementos de las matrices pueden ser extraídos usando corchetes, con los índices de fila y columna separados por coma. Deja el índice en blanco para obtener la fila completa como un vector. Usa el índice del vector para obtener múltiples filas o columnas como una matriz más pequeña:
> m[2,4]
[1] 11
> m[2,]
[1] 2 5 8 11
> m[,3:4]
[,1] [,2]
[1,] 7 10
[2,] 8 11
[3,] 9 12
Las tramas de datos son estructuras que se asemejan a las estructuras encontradas en las bases de datos relacionales como Postgres o MySQL. Cada fila puede ser pensada como un registro con las columnas siendo los campos en la base de datos. Como en una base de datos, cada campo debe ser del mismo tipo en cada registro.
En varias formas, trabajan como matrices pero también puedes obtener un conjunto de columnas por nombre, usando la notación $-.
> d = data.frame(x=1:10,y=1:10,z=runif(10)) # z is 10 random numbers
> d
x y z
1 1 1 0.44128080
2 2 2 0.09394331
3 3 3 0.51097462
4 4 4 0.82683828
5 5 5 0.21826740
6 6 6 0.65600533
7 7 7 0.59798278
8 8 8 0.19003625
9 9 9 0.24004866
10 10 10 0.35972749
> d$z
[1] 0.44128080 0.09394331 0.51097462 0.82683828 0.21826740 0.65600533
[7] 0.59798278 0.19003625 0.24004866 0.35972749
> d$big = d$z > 0.6 # d$big is now a boolean true/false value
> d[1:5,]
x y z big
1 1 1 0.44128080 FALSE
2 2 2 0.09394331 FALSE
3 3 3 0.51097462 FALSE
4 4 4 0.82683828 TRUE
5 5 5 0.21826740 FALSE
> d$name = letters[1:10] # create a new field of characters
> d[1:5,]
x y z big name
1 1 1 0.44128080 FALSE a
2 2 2 0.09394331 FALSE b
3 3 3 0.51097462 FALSE c
4 4 4 0.82683828 TRUE d
5 5 5 0.21826740 FALSE e
Hay muchos paquetes para manipular datos espaciales. Algunos están incluídos y algunso puede ser bajados desde CRAN.
Aquí vamos a cargar dos archivos shape, los límites del país y los lugares populares desde los datos de Natural Earth. Usamos dos paquetes extras para obtener la funcionalidad espacial:
> library(sp)
> library(maptools)
> countries = readShapeSpatial("/usr/local/share/data/natural_earth/10m_admin_0_countries.shp")
> places = readShapeSpatial("/usr/local/share/data/natural_earth/10m_populated_places_simple.shp")
> plot(countries)
Esto nos da un mapa simple del mundo:
Cuando un conjunto de datos OGR es introducido en R obtenemos como respuesta un objeto que se comporta de muchas formas como una trama de datos. Podemos usar el campo ADMIN para obtener sólo el Reino Unido:
> uk = countries[countries$ADMIN=="United Kingdom",]
> plot(uk); axis(1); axis(2)
Esto parece un poco aplastado para los que vivimos aquí, ya que estamos familiarizados con un sistema de coordenadas centrado en nuestra latitud. En este momento, el objeto no tiene un sistema de coordenadas asignado y podemos verificarlo con algunas funciones:
> proj4string(uk)
[1] NA
NA es un indicador de falta de datos. Necesitamos asignar un CRS al objeto antes de que podamos tranformarlo con la función spTransform del paquete rgdal. Lo transformamos a EPSG:27700 que es el sistema del servicio estatal de cartografía de Gran Bretaña:
> proj4string(uk)=CRS("+init=epsg:4326")
> library(rgdal)
> ukos = spTransform(uk,CRS("+init=epsg:27700"))
> proj4string(ukos)
[1] " +init=epsg:27700 +proj=tmerc +lat_0=49 +lon_0=-2 +k=0.9996012717 +x_0=400000 +y_0=-100000 +ellps=airy +datum=OSGB36 +units=m +no_defs
+towgs84=446.448,-125.157,542.060,0.1502,0.2470,0.8421,-20.4894"
> plot(ukos);axis(1);axis(2)
Esto dibuja el mapa de los datos transformados. Ahora queremos agregar algunos puntos del conjunto de lugares populares. Otra vez, filtramos los puntos y los transformamos:
> ukpop = places[places$ADM0NAME=="United Kingdom",]
> proj4string(ukpop)=CRS("+init=epsg:4326")
> ukpop = spTransform(ukpop,CRS("+init=epsg:27700"))
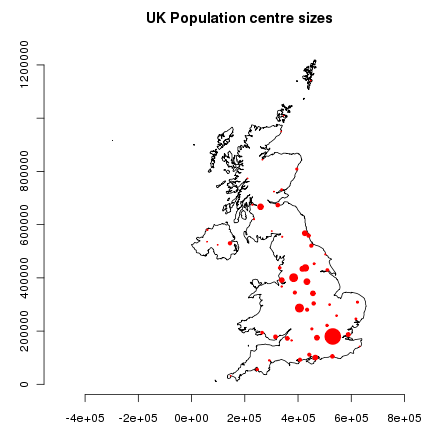
Agregamos estos puntos al mapa base, escalamos su tamaño de acuerdo a la raíz cuadrada de su población (eso define un símbolo con área proporcional a la población), y definimos el color del símbolo y el estilo de los caracteres:
> points(ukpop,cex=sqrt(ukpop$POP_MAX/1000000),col="red",pch=19)
> title("UK Population centre sizes")
y nuestra imagen final aparece:
En el pasado, la documenación de los paquetes de R tendían a ser simplemente páginas de ayuda para cada función. Ahora, los autores de los paquetes se han animado a escribir una ‘viñeta’ como una introducción amigable al paquete. Si ejecutas la función vignette() sin argumentos, obtendrás una lista de viñetas de tu sistema. Prueba vignette("sp") para un ligera introducción técnica a las estructuras espaciales de R, o vignette("spdep") para análisis estadístico de autocorrelación espacial. La función vignette("gstat") te da un tutuorial de cómo usar ese paquete para interpolaciones espaciales, incluyendo Kriging.
Para información general acerca de R, prueba con Introduction to R o cualquier documentación de la página principal del Proyecto R.
Para más información en los aspectos espaciales de R, el mejor lugar para empezar es probablemente R Spatial Task View
También podrías mirar la página R-Spatial para obtener más links, incluyendo información acerca de la lista de mail R-sig-Geo.