
R Quickstart für Geodaten¶
R ist eine freie Software-Umgebung für statistische Berechnungen und Grafik.
Dieser Quick Start beschreibt, wie man:
- R für einfache Arithmetik benutzt
- ein Shapefile lädt und darstellt
- eine Koordinatentransformation durchführt
- Datenpunkte auf eine Karte plottet
R starten¶
Entweder:
- Wähle
R Statisticsaus dem Menü Geospatial - Spatial Tools - ein Konsolenfenster mit R startet.- Geben Sie
Rin einem Konsolenfenster ein. R startet dann in dem Fenster.
Keine Angst vor der Kommandozeile - es ist eine Quelle großer Macht. Mit der Aufwärts- und Abwärts Pfeiltasten können Sie Befehle zurückholen und die Tastenkombination CTRL-C gibt den Eingabepromt wieder, wenn Sie mal irgendwo stecken bleiben.
R beenden¶
Fast alles in R ist eine Funktion, inklusive der Funktion zum Beenden. Tippen Sie q() und drücken dann Return. Wenn Sie nur q tippen, sehen Sie den Quellcode der Funktion q.
R fragt Sie dann, ob Sie die letzte Session als R data image speichern wollen. Wenn Sie R aus einem Ordner mit einer .RData Datei starten, werden alle Daten daraus wieder integriert.
R Einführung¶
R ist im Wesentlichen ein Kommandozeilen-Programm, obwohl auch grafische Benutzeroberflächen zur Verfügung stehen. Sie geben einen Code-Zeile ein, drücken die Eingabetaste, und der R-Interpreter wertet sie aus und druckt das Ergebnis.
Sie können mit einer einfachen Arithmetik starten
> 3*2
[1] 6
> 1 + 2 * 3 / 4
[1] 2.5
> sqrt(2)
[1] 1.414214
> pi * exp(-1)
[1] 1.155727
Und so weiter. Eine vollständige Palette von Arithmetik, trigonometrischen und statistischen Funktionen sind integriert, und weitere tausende Pakete im CRAN Archiv.
Der Hauptpprompt in R ist >, aber es gibt auch die Fortsetzungs-Eingabeaufforderung +, die erscheint, wenn R mit mehr rechnet, damit ein gültiger Ausdruck enststeht. Das werden Sie sehen, wenn Sie z.B. vergessen, eine Klammer zu schliessen.
> sqrt(
+ 2
+ )
[1] 1.414214
Daten erstellen¶
Sie fragen sich vielleicht, was die geheimnisvolle ‚1‘ in eckigen Klammern in der Ausgabe ist. Das zeigt Ihnen, dass das Ergebnis eine Zahl ist. R kann Dinge in eindimensionalen Vektoren, zweidimensionalen Matrizen und mehrdimensionalen Arrays speichern. Es gibt viele Funktionen, die diese Dinge erzeugen können. Hier ist eine einfache Sequenz:
> seq(1, 5, len=10)
[1] 1.000000 1.444444 1.888889 2.333333 2.777778 3.222222 3.666667 4.111111
[9] 4.555556 5.000000
Jetzt können Sie sehen, dass die `` [9] `` sagt, dass die 4,555 der neunte Wert in dem Vektor ist.
Wenn Sie eine Matrix konstruieren, bekommen Sie Zeilen- und Spaltenbeschriftungen:
> m = matrix(1:12, 3, 4)
> m
[,1] [,2] [,3] [,4]
[1,] 1 4 7 10
[2,] 2 5 8 11
[3,] 3 6 9 12
Elemente von Matrizen extrahiert man mit eckigen Klammern, mit Zeilen und Spalten Indizes durch Komma getrennt. Lassen Sie einen Index leer, um eine ganze Zeile als Vektor zu erhalten. Verwenden Sie einen Vektor Index, um mehrere Zeilen oder Spalten als eine kleinere Matrix zu erhalten:
> m[2,4]
[1] 11
> m[2,]
[1] 2 5 8 11
> m[,3:4]
[,1] [,2]
[1,] 7 10
[2,] 8 11
[3,] 9 12
Daten-Frames sind Datenstrukturen, die die Art der Struktur in einem RDBMS wie Postgres oder MySQL spiegeln. Jede Zeile kann als ein Datensatz gedacht werden, mit Spalten, wie Felder in einer Datenbank. Wie in einer Datenbank müssen die einzelnen Felder den gleichen Typ für jeden Datensatz besitzen.
In vielerlei Hinsicht funktionieren sie wie Matrizen, aber Sie können die Spalten auch über Namen ansprechen mit $-Notation:
> d = data.frame(x=1:10, y=1:10, z=runif(10)) # z is 10 random numbers
> d
x y z
1 1 1 0.44128080
2 2 2 0.09394331
3 3 3 0.51097462
4 4 4 0.82683828
5 5 5 0.21826740
6 6 6 0.65600533
7 7 7 0.59798278
8 8 8 0.19003625
9 9 9 0.24004866
10 10 10 0.35972749
> d$z
[1] 0.44128080 0.09394331 0.51097462 0.82683828 0.21826740 0.65600533
[7] 0.59798278 0.19003625 0.24004866 0.35972749
> d$big = d$z > 0.6 # d$big is now a boolean true/false value
> d[1:5,]
x y z big
1 1 1 0.44128080 FALSE
2 2 2 0.09394331 FALSE
3 3 3 0.51097462 FALSE
4 4 4 0.82683828 TRUE
5 5 5 0.21826740 FALSE
> d$name = letters[1:10] # create a new field of characters
> d[1:5,]
x y z big name
1 1 1 0.44128080 FALSE a
2 2 2 0.09394331 FALSE b
3 3 3 0.51097462 FALSE c
4 4 4 0.82683828 TRUE d
5 5 5 0.21826740 FALSE e
Karten laden¶
Es gibt viele Pakete für räumliche Datenmanipulation und deren statistische Analyse. Einige sind bereits hier enthalten, und einige können vom CRAN Server heruntergeladen werden.
Hier werden wir zwei Shapefiles herunterladen - die Landesgrenzen und die besiedelten Orte aus dem Natural Earth Datensatz. Wir verwenden zwei Add-on Pakete, um die notwendige Funktionalität zu bekommen:
> library(sf) # Simple Features manipulation Library
> library(ggplot2) # Plotting library
> countries <- st_read(dsn = "~/data/natural_earth2/ne_10m_admin_0_countries.shp")
> places <- st_read(dsn = "~/data/natural_earth2/ne_10m_populated_places.shp")
> ggplot(countries) + geom_sf()
Damit stellen wir eine einfache Weltkarte dar:
Wenn ein OGR Datensatz auf diese Weise nach R eingelesen wird, bekommen wir ein Objekt, dass sich in vielerlei Hinsicht wie ein Daten Frame verhält. Wir können die Spalte COUNTRY benutzen, um eine Teilmenge der Weltdaten, nämlich nur das UK zu bekommen:
- ::
- > uk <- countries[countries$admin == ‚United Kingdom‘,] > ggplot(uk) + geom_sf()
This looks a bit squashed to anyone who lives here, since we are more familiar with a coordinate system centred at our latitude. Currently the object doesn’t have a coordinate system assigned to it.
We need to assign a CRS to the object before we can transform it with the sf::st_transform function from the sf package. We transform to EPSG:27700 which is the Ordnance Survey of Great Britain grid system:
- ::
- > ukos <- st_transform(uk,27700) > ggplot(ukos) + geom_sf()
Dies zeichnet eine Karte der transformierten Daten. Nun wollen wir einige Punkte aus dem besiedelte Orte Datensatz ergänzen. Wieder erstellen wir eine Teilmenge der Punkte und transformieren sie zu Ordnance Survey Grid Reference-Koordinaten:
- ::
- > ukpop <- places[places$SOV0NAME == ‚United Kingdom‘,] > ukpop <- st_transform(ukpop,27700)
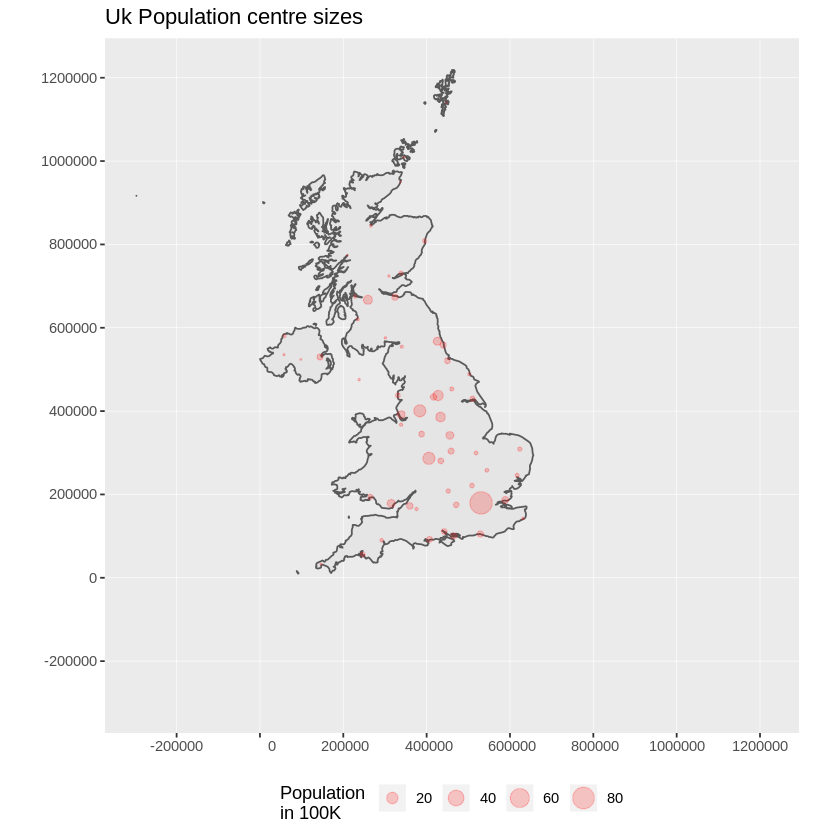
We add these points to the base map, scaling their size by scaled square root of the population (because that makes a symbol with area proportional to population), set the colour to red and the plotting character to a solid blob:
- ::
- > ggplot() + > geom_sf(data = ukos) + # add UK shape to the map > geom_sf(data = ukpop, # add the Populated places > aes(size = ukpop$POP_MAX/100000), # fix size of points (by area) > colour = ‚red‘, alpha = 1/5) + # set points colour and transparency > coord_sf(crs = 27700, datum= sf::st_crs(27700), # set a bounding box > xlim = st_bbox(ukos[c(1,3)]), # for the map > ylim = st_bbox(ukos[c(2,4)]) > ) + > ggtitle(‚Uk Population centre sizes‘) + # set the map title > theme(legend.position = ‚bottom‘) + # Legend position > scale_size_area(name = ‚Population nin 100K‘) # 0 value means 0 area + legend title
und unsere Ausgabekarte erscheint:
Vignetten¶
In the past the documentation for R packages tended to be tersely-written help pages
for each function. Now package authors are encouraged to write a ‚vignette‘ as a friendly
introduction to the package. If you just run the vignette() function with no arguments
you will get the list of those vignettes on your system. Try vignette("sf1") for a
slightly technical introduction to the R spatial package.
Weiterführende Links¶
Für allgemeine Informationen über R, versuchen Sie die offizielle Seite Introduction to R oder eine andere Dokumentation von der Hauptseite des R Projekts.
Für weitere Informationen über räumliche Aspekte von R, ist wahrscheinlich das R Spatial Task View am hilfreichsten.
You might also want to check out the R-Spatial page.