
R Quickstart¶
Rはフリーの統計計算および作図環境です。
このクイックスタートでは以下の内容を紹介します:
- Rによる簡単な計算
- Shapefileの読み込みとその地図化
- 座標変換
- 地図上への点データのプロット
Rの起動¶
以下のいずれかのやり方で起動します:
R 空間解析機能をメニューの空間ツールセクションから選択 - Rの起動したターミナルウィンドウが開きます。- ターミナルで
Rと入力すると、Rが起動します。
コマンドラインはそんなに怖いものではなく、とても便利なものです。 ミスタイプをしても十字キーの上下でコマンド履歴を呼び出し編集することができます。 表示が止まってしまった場合は CTRL-C を入力することで復帰することができます。
Rの終了¶
Rでは終了動作も含めて何をするにも関数を使います。
q() と入力してみてください。
ちなみにもし q と入力してしまうと q 関数のソースコードが表示されます。
終了コマンドを入力するとワークスペースをRイメージファイルとして保存するかどうかを聞かれます。
.RData ファイルのある場所からRを開始するとすべてのワークスペースを復元してくれます。
Rを始める¶
Rは基本的にコマンドラインプログラムですが、グラフィックユーザーインターフェースも利用可能です。 ターミナルでコードを入力すると、Rインタープリターがそれを解釈して結果を出力します。
簡単な計算をしてみましょう
> 3*2
[1] 6
> 1 + 2 * 3 / 4
[1] 2.5
> sqrt(2)
[1] 1.414214
> pi * exp(-1)
[1] 1.155727
といったように、さまざまな算術・三角・統計計算の関数が組み込まれており、 何千ものパッケージが CRAN アーカイブから利用可能です.
Rのプロンプトは > ですが、
コマンドを中途半端に入力した場合は + という続きの入力を促すプロンプトが表示されます。
たとえば閉じ括弧を忘れたりすると表示されます。
> sqrt(
+ 2
+ )
[1] 1.414214
データ作成¶
出力結果の左端の数字の1の入った角括弧は何だろうと疑問に思うかもしれません。 これは出力結果の数は1個という意味です。 Rでは一次元、二次元行列、多次元配列としてデータを保持することができます。 このようなデータを生成する方法は多くありますが、簡単な手順としては:
> seq(1, 5, len=10)
[1] 1.000000 1.444444 1.888889 2.333333 2.777778 3.222222 3.666667 4.111111
[9] 4.555556 5.000000
[9] という表示は 4.555 の値はベクトルの中の9番目の値を意味します。
行列データを作成すると行列のラベルも生成されます:
> m = matrix(1:12, 3, 4)
> m
[,1] [,2] [,3] [,4]
[1,] 1 4 7 10
[2,] 2 5 8 11
[3,] 3 6 9 12
行列の要素は角括弧とカンマで区切った行列のインデックス値を使って抽出することができます。 とある一行をまとめて抽出する場合は行のインデックス値を空白にします。 複数の行や列をまとめて抽出する場合は行や列のインデックス値をベクトルとして指定します:
> m[2,4]
[1] 11
> m[2,]
[1] 2 5 8 11
> m[,3:4]
[,1] [,2]
[1,] 7 10
[2,] 8 11
[3,] 9 12
データフレームはPostgresのようなRDBMSに見られるようなデータ構造です。 それぞれの行はデータベースでいうフィールド列を持ったレコードとして扱われます。 データベースと同様にそれぞれフィールドは同じデータタイプである必要があります。
行列データど同様に扱うこともできますが、$マークを用いて列を指定することもできます:
> d = data.frame(x=1:10, y=1:10, z=runif(10)) # z is 10 random numbers
> d
x y z
1 1 1 0.44128080
2 2 2 0.09394331
3 3 3 0.51097462
4 4 4 0.82683828
5 5 5 0.21826740
6 6 6 0.65600533
7 7 7 0.59798278
8 8 8 0.19003625
9 9 9 0.24004866
10 10 10 0.35972749
> d$z
[1] 0.44128080 0.09394331 0.51097462 0.82683828 0.21826740 0.65600533
[7] 0.59798278 0.19003625 0.24004866 0.35972749
> d$big = d$z > 0.6 # d$big is now a boolean true/false value
> d[1:5,]
x y z big
1 1 1 0.44128080 FALSE
2 2 2 0.09394331 FALSE
3 3 3 0.51097462 FALSE
4 4 4 0.82683828 TRUE
5 5 5 0.21826740 FALSE
> d$name = letters[1:10] # create a new field of characters
> d[1:5,]
x y z big name
1 1 1 0.44128080 FALSE a
2 2 2 0.09394331 FALSE b
3 3 3 0.51097462 FALSE c
4 4 4 0.82683828 TRUE d
5 5 5 0.21826740 FALSE e
地図データの読み込み¶
空間データの操作や統計を行えるパッケージは多くあります。 いくつかはすでに含まれており、CRANから追加でダウンロードすることもできます。
ここではNatural Earthから入手した2つのshapefile (国境と人口分布) を読み込みます。 空間解析のための2つのパッケージを使用します:
> library(sp)
> library(maptools)
> countries = readShapeSpatial("/usr/local/share/data/natural_earth2/ne_10m_admin_0_countries.shp")
> places = readShapeSpatial("/usr/local/share/data/natural_earth2/ne_10m_populated_places.shp")
> plot(countries)
以上の操作を行うとシンプルな世界地図が表示されるはずです:
このようにOGRデータセットをRに読み込むと、データフレームのように様々な方法でデータを扱うことができるようになります。
admin フィールドを使ってイギリスのみを抽出します:
> uk = countries[countries$admin == "United Kingdom",]
> plot(uk); axis(1); axis(2)
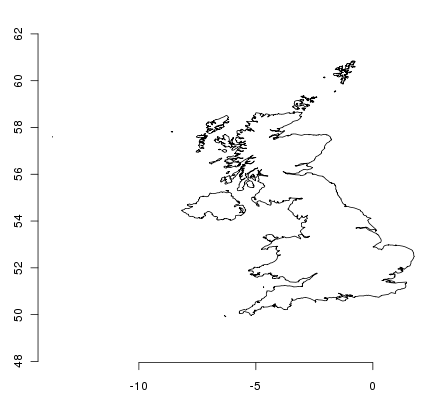
ここに住んでいる人にとってはちょっと変に見えるかもしれません、 なぜなら私達はこの緯度帯を中心にした座標系のほうが見慣れているからです。 今のところ、このオブジェクトには座標系が割り当てられていません。 これは関数を使うことで確認することができます:
> proj4string(uk)
[1] NA
NA はデータがないことを意味します。
rgdal パッケージの spTransform 関数で座標系変換をする前に座標系を割り当てる必要があります。
それでは EPSG:27700 座標系 (Ordnance Survey of Great Britain grid system) に座標系変換をしてみます:
> proj4string(uk) = CRS("+init=epsg:4326")
> library(rgdal)
> ukos = spTransform(uk, CRS("+init=epsg:27700"))
> proj4string(ukos)
[1] " +init=epsg:27700 +proj=tmerc +lat_0=49 +lon_0=-2 +k=0.9996012717 +x_0=400000 +y_0=-100000 +ellps=airy +datum=OSGB36 +units=m +no_defs
+towgs84=446.448,-125.157,542.060,0.1502,0.2470,0.8421,-20.4894"
> plot(ukos); axis(1); axis(2)
座標系変換したベースマップをプロットしています。 続いて人口分布データを使っていくつか点をプロットしてみたいと思います。 では Ordnance Survey Grid Reference 座標系に変換したい点を抽出してみます:
> ukpop = places[places$ADM0NAME == "United Kingdom",]
> proj4string(ukpop) = CRS("+init=epsg:4326")
> ukpop = spTransform(ukpop, CRS("+init=epsg:27700"))
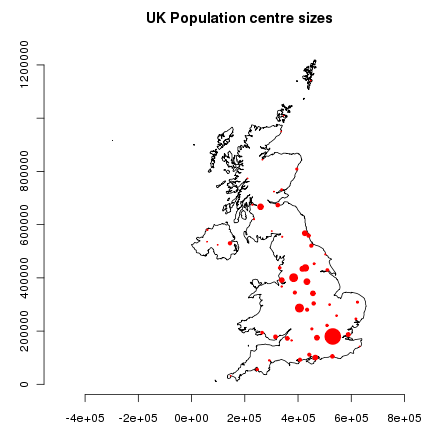
ベースマップに赤い丸を人口の平方根で大きさを決めて追加し (人口の大きさと丸の面積の比率を一定にするため) 、 文字を追加します:
> points(ukpop, cex=sqrt(ukpop$POP_MAX/1000000), col="red", pch=19)
> title("UK Population centre sizes")
出力結果はこちらです:
Vignettes¶
これまでのRパッケージのドキュメントではそれぞれの関数について簡潔に書かれている傾向がありました。
現在ではパッケージの開発者はわかりやすいパケージの紹介として ‘vignette’ を書くことが推奨されています。
vignette() 関数を引数なしで実行するとシステム上にある vignette のリストが表示されます。
vignette("intro_sp") と入力するとR空間パッケージについてのやや技術的な紹介を見ることができます。
vignette("gstat") と入力するとクリギングなどの空間補間についてのパッケージのチュートリアルを見ることができます。
参照情報¶
Rに関しての情報全般については Introduction to R または公式サイト R Project ドキュメント群が参考になります.
Rの空間分析について知る上で一番の場所は R Spatial Task View です。
また、sourceforgeの R-Spatial にもR-sig-Geoメーリングリストなどの様々な情報やリンクがあります。