
Guida Rapida a R¶
R è un ambiente software libero per il calcolo statistico e la grafica.
Questa rapida introduzione ad R descrive come:
- utilizzare R per semplici operazioni aritmetiche
- caricare dati e creare una mappa da un file in formato shape
- operare una trasformazione di coordinate
- plottare punti su una mappa
Avviare R¶
Opzioni disponibili:
- Scegliere
R Statisticsdalla sezione Spatial Tools del menu - una finestra terminale apparirà con R già avviato.- Digitare
Ral prompt di una riga di comando shell. R verrà avviato nel terminale stesso.
Non temete la riga di comando - è uno strumento molto potente. Utilizzare le frecce su e giù per richiamare i comandi già utilizzati e fare correzioni è di grande aiuto. Nel caso il programma si blocchi digitando CTRL-C dovreste tornare al prompt della shell.
Terminare R¶
Quasi tutto in R è una funzione, inclusi i comandi per terminare R stesso. Digitare
q() e premere il tasto INVIO. Digitando solo q (senza le parentesi) verrà mostrato
il codice sorgente per la funzione q.
R chiederà se si vuole salvare l’ambiente di lavoro come un file immagine dati di R.
Quando R verrà avviato nuovamente da una cartella contenente un file .RData verranno
ripristinati tutti i dati precedentemente salvati nel file immagine.
Cominciare ad utilizzare R (Beginning R)¶
R è essenzialmente un programma a linea di comando (CLI, command line interface) sebbene siano disponibili interfacce utente grafiche (GUI, grafical user interface). Digitando una riga di codice al prompt e premendo INVIO, l’interprete di R valuta il comando e stampa il risultato.
Si può cominciare con semplici operazioni aritmetiche:
> 3*2
[1] 6
> 1 + 2 * 3 / 4
[1] 2.5
> sqrt(2) #square root -> radice quadrata
[1] 1.414214
> pi * exp(-1)
[1] 1.155727
E cosi via. Un’intera gamma di funzioni airtmetiche, trigonometriche e statistiche sono già installate (built in) e molte altre migliaia sono disponibili all’interno di pacchetti localizzati nell’archivio on-line CRAN <http://cran.r-project.org/>.
Il prompt principale in R è >, sebbene esista anche il prompt di continuazione +, che
apapre quando R si aspetta che ulteriori input siano necessari per rendere valida un espressione.
Quest’ultimo compare nel caso in cui ci si dimentichi di chiudere le parentesi.
> sqrt(
+ 2
+ )
[1] 1.414214
Costruire Dati (Building Data)¶
Qualcuno potrebbe chiedersi cosa voglia dire quel misterioso ‘uno’ racchiuso tra parentesi quadre nell’output. Sta dicendo che il risultato consiste di un solo numero. R può immagazinare “cose” vettori mono-dimensionali, matrici bi-dimensionali e array multi-dimensionali. Ci sono molte funzioni che possono generare queste cose. Di seguito una semplice sequenza:
> seq(1, 5, len=10)
[1] 1.000000 1.444444 1.888889 2.333333 2.777778 3.222222 3.666667 4.111111
[9] 4.555556 5.000000
Ora si può capire come il [9] stia dicendo che 4.555 è il nono valore del vettore.
Quando si costruisce una matrice verranno mostrate etichette di righe e colonne:
> m=matrix(1:12, 3, 4)
> m
[,1] [,2] [,3] [,4]
[1,] 1 4 7 10
[2,] 2 5 8 11
[3,] 3 6 9 12
Gli elementi delle matrici possono essere estratti utilizzando le parentesi quadre, con gli indici di righe e colonne separate da virgole. Lasciando uno spazio bianco al posto di un indice restituirà l’intera riga (o colonna) come vettore. Per ottenere più righe o colonne come una matrice più piccola utilizzare gli indici di un vettore:
> m[2,4]
[1] 11
> m[2,]
[1] 2 5 8 11
> m[,3:4]
[,1] [,2]
[1,] 7 10
[2,] 8 11
[3,] 9 12
I ‘data frames’ sono strutture di dati che rispecchiano le strutture i tipi di strutture ritrovabili negli RDBMS (relational data base management system) come Postgres o MySQL. Ogni riga può essere pensata come un ‘record’ mentre le colonne cosituiscono i da campi di un database. Come in un data base ogni campo deve essere dello stesso tipo per ogni record.
Per molti versi funzionano come le matrici. In aggiunta è possibile richiamare e settare le colonne per nome utilizzando la notazione $:
> d = data.frame(x=1:10, y=1:10, z=runif(10)) # z è composto da 10 numeri random
> d
x y z
1 1 1 0.44128080
2 2 2 0.09394331
3 3 3 0.51097462
4 4 4 0.82683828
5 5 5 0.21826740
6 6 6 0.65600533
7 7 7 0.59798278
8 8 8 0.19003625
9 9 9 0.24004866
10 10 10 0.35972749
> d$z
[1] 0.44128080 0.09394331 0.51097462 0.82683828 0.21826740 0.65600533
[7] 0.59798278 0.19003625 0.24004866 0.35972749
> d$big = d$z > 0.6 # d$big is now a boolean true/false value
> d[1:5,]
x y z big
1 1 1 0.44128080 FALSE
2 2 2 0.09394331 FALSE
3 3 3 0.51097462 FALSE
4 4 4 0.82683828 TRUE
5 5 5 0.21826740 FALSE
> d$name = letters[1:10] # create a new field of characters
> d[1:5,]
x y z big name
1 1 1 0.44128080 FALSE a
2 2 2 0.09394331 FALSE b
3 3 3 0.51097462 FALSE c
4 4 4 0.82683828 TRUE d
5 5 5 0.21826740 FALSE e
Caricare dati da un mappa¶
Esistono molti pacchetti per la manipolazione e le statistiche di dati spaziali. Alcuni sono inclusi qui altri possono essere scaricati da CRAN.
Qui mostreremo come caricare due shapefiles - i confini nazionali e le località popolate dai dati di Natural Earth. Usiamo due pacchetti installati (add-on) per ottenere le funzioalità spaziali:
> library(sp)
> library(maptools)
> countries = readShapeSpatial("/usr/local/share/data/natural_earth/ne_10m_admin_0_countries.shp")
> places = readShapeSpatial("/usr/local/share/data/natural_earth/ne_10m_populated_places.shp")
> plot(countries)
Questo ci dà una semplice mappa del mondo:
Quando un dataset OGR viene letto in R in questo modo otteniamo un oggetto che per molti aspetti
si comporta come un data frame. Possiamo utilizzare il campo ADMIN per fare un subset dei dati
del mondo e ottenere, ad esempio, la Gran Bretagna (UK, United Kingdom):
> uk = countries[countries$ADMIN == "United Kingdom",]
> plot(uk); axis(1); axis(2)
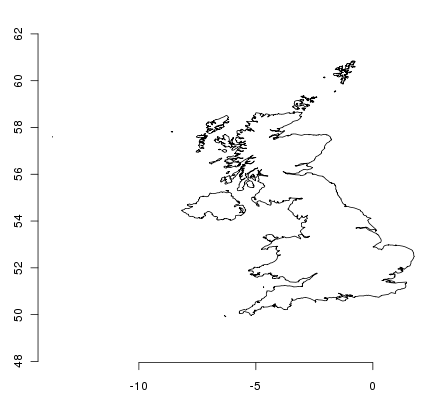
Questa immagine può apparire un po’ schiacciata a chiunque viva in Gran Bretagna poichè siamo abituati con sistemi di coordinate centrate alle nostre latitudini. Attualmente l’oggetto non ha un sistema di coordinate assegnato - possiamo verificare ciò con qualche funzione:
> proj4string(uk)
[1] NA
NA è un indicatore per i dati mancanti. Abbiamo bisogno di assegnare un CRS (sistema di riferimento
di coordinate) all’oggetto prima di poter operare una trasformazione con la funzione spTransform del
pacchetto rgdal. Trasformiamo in EPSG:27700 che rappresenta l’ Ordnance Survey of Great Britain grid system:
> proj4string(uk) = CRS("+init=epsg:4326")
> library(rgdal)
> ukos = spTransform(uk, CRS("+init=epsg:27700"))
> proj4string(ukos)
[1] " +init=epsg:27700 +proj=tmerc +lat_0=49 +lon_0=-2 +k=0.9996012717 +x_0=400000 +y_0=-100000 +ellps=airy +datum=OSGB36 +units=m +no_defs
+towgs84=446.448,-125.157,542.060,0.1502,0.2470,0.8421,-20.4894"
> plot(ukos); axis(1); axis(2)
Questo comando plotta la mappa di base dei dati trasformati. Ora vogliamo aggiungere qualche punto dal data set dei posti popolati (populated places). Ancora una volta operiamo un estrazione di un sottoinsieme (subset) di dati che ci interessano e li trasformiamo nel sistema di coordinate dell’Ordnance Survey Grid Reference:
> ukpop = places[places$ADM0NAME == "United Kingdom",]
> proj4string(ukpop) = CRS("+init=epsg:4326")
> ukpop = spTransform(ukpop, CRS("+init=epsg:27700"))
Aggiungiamo questi punti alla mappa di base, scalando la loro dimensione in base alla radice quadrata della popolazione (in modo da rendere l’area del simbolo proporzionale alla popolazione), settiamo i colori (col=) in rosso e i caratteri (pch=) come punti pieni:
> points(ukpop, cex=sqrt(ukpop$POP_MAX/1000000), col="red", pch=19)
> title("UK Population centre sizes")
e la nostra immagine finale appare:
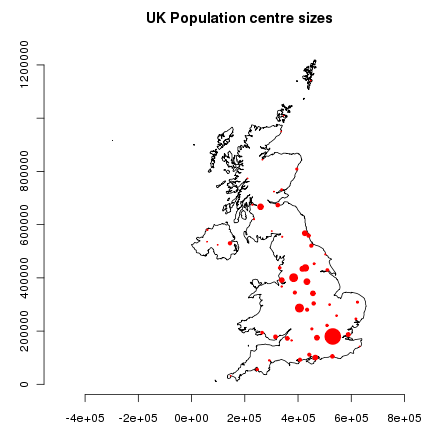
Vignettes¶
Nel passato la documentazione per R consisteva in pagine di aiuto scritte concisamente per ogni funzione.
Oggi, gli autori dei pacchetti sono incoraggiati a scrivere ‘vignette come introduzione intuitiva al
pacchetto. Digitando solo la funzione vignette() senza nessun argomento si ottiene una lista di
quelle vignette presenti sul proprio sistema. Prova vignette("intro_sp") per una introduzione poco tecnica
ai pacchetti che utilizzano dati spaziali presenti in R. vignette("gstat") fornisce un tutorial per
l’uso del pacchetto per l’interpolazione spaziale incluso il Kriging.
Approfondimenti¶
Per informazioni generali circa R, si può consultare il manuale officiale Introduzione a R <http://cran.r-project.org/doc/manuals/R-intro.html> o qualsiasi altra documentazione presente sul sito principale R Project <http://www.r-project.org/>.
Per maggiori informazioni sugli aspetti spaziali di R, il miglior posto per iniziare è probabilmente R Spatial Task View <http://cran.r-project.org/web/views/Spatial.html>.
Potrebbe anche essere interessante dare un’occhiata alla pagina R-Spatial <http://r-spatial.sourceforge.net/> su sourceforge per qualche link aggiuntivo che include informazioni sulla mailing list R-sig-Geo.